Towards the first release of Turbo-geth
It has been more than two years since turbo-geth project started. Now we are almost there. This post will explain the criteria we will use for determining when the release is ready, and what to expect from turbo-geth in its first release. First, we will describe the current limitations (compared to other Ethereum implementations), and then go over things that are the reason for turbo-geth to exist - performance and architecture.
When is it going to be ready?
It is now ready for public alpha stage. We encourage people to try it out, and talk to us about results, and report issues. Though the sync (and with it, the creation of the initial database) with the Ethereum main net has been massively improved due to the new architecture, it still takes non-trivial amount of time (several days).
We call this new architecture “staged sync”, and it will be explained in more detals further down.
When are we going from “alpha” to “beta”?
Currently, the main criterion for us to go from alpha to beta is the (somewhat subjective) understanding of how “in control” of code our team is. At this moment the feeling is that we are mostly in control (meaning that we can identify and debug issues without too much digging into some unknown code), except for certain parts that pertain to devp2p, downloading of headers and blocks, and reactions on the new blocks. The code we are currently using has not been designed for staged sync architecture, and assumes that all “stages” are happening concurrently. Therefore, this code does much more than we need, and is unnecessarily complex for what we actually need. We also often experience stalling sometimes.
In order to address this, we have started a redesign of block header downloading, which should result in a more suitable, better understood code Here is current Work-In-Progress documentation (which is also accompanied by a Proof Of Concept implementation and tests): https://github.com/ledgerwatch/turbo-geth/blob/headers-poc/docs/programmers_guide/header_download.md
Distribution
We would like to keep concentrating on developing and optimising the code, therefore we will not be publishing any binaries. Our first users would need to build from source. This may change in the future, if we find it being crucial.
No fast sync, warp sync or any other snapshot sync
In the first release, the only way to synchronise with the Ethereum network will be to download block headers, download block bodies, and execute all the blocks from genesis to the current head of the chain. Although this may sound like a non-starter, we have managed to make this process very efficient. As our next steps, we would like to develop a version of snapshot sync, which is as simple as possible (as simple as downloading a file from a torrent), initial description and discussion can be found here: https://ethresear.ch/t/simpler-ethereum-sync-major-minor-state-snapshots-blockchain-files-receipt-files/7672
Work is underway on the initial code that will utilise BitTorrent for downloading headers and blocks.
GPL license
Since turbo-geth is a derivative of go-ethereum, it inherits General Public License 3.0. We will not be able to relicense the code at any point, but we may, in the future, shift some or all parts of the functionality into external libraries that would be released under more permissive licenses than GPL3.
Licence and language migration plan (out of scope for the release)
This would be an experiment which goes beyond technical, but it is rather trying to find out whether it is possible to build a financially sustainable operation around a product like Ethereum implementation. So far very few had tried and we do not see a lot of success. Lots of people believe that this lack of success has to do with the limitations of the GPL licence:
- It limits the engagement of big tech companies
- Makes it difficult for small specialists to monetalise customisation work, therefore depriving the product ecosystem of motivated participants
We would like to try to get to Apache 2.0 licence. But that means basically re-writing the product. And we do not see a good way of re-writing turbo-geth in Go without a lot of “rewriting for rewriting sake”, which is likely to be counterproductive. Also, going “into a cave” again and re-writing it from scratch is not something we would like to do. I would prefer gradual migration of the product that always works - in my experience this approach has much fewer risks. C++ seems to be a good first target for migration, for a few reasons:
- The original eth C++ client is de-facto dead, so we might get some help from people who used to work on it
- Interfacing between Go and C/C++ is probably easier than to any other languages
- We already found some great components to start with - evm1, lmdb
- If we want to migrate to other languages, like Rust, in the future, it will be easier to do that from C++, again because of the language interfacing. Migration
Go => (Go;Rust) => Rust is likely to be more troublesome than the migration Go => (Go;C++) => C++ => (C++;Rust) => Rust, though this is not currently a goal.
Work is underway to convert certain stages of the sync process to C++.
Separation of JSON RPC and future of architecture during migration
Presently, turbo-geth, like go-ethereum runs most of its its functionality in a single, monolithic process. We have started some experiments on separating the JSON RPC functionality out into a separate process (RPC daemon), to support more flexible scaling of “JSON RPC farms”. We are planning to experiment with separating out another networking component, which is currently handling peer discovery and devp2p, into a separate process, called Sentry. The resulting architecture would look like this:
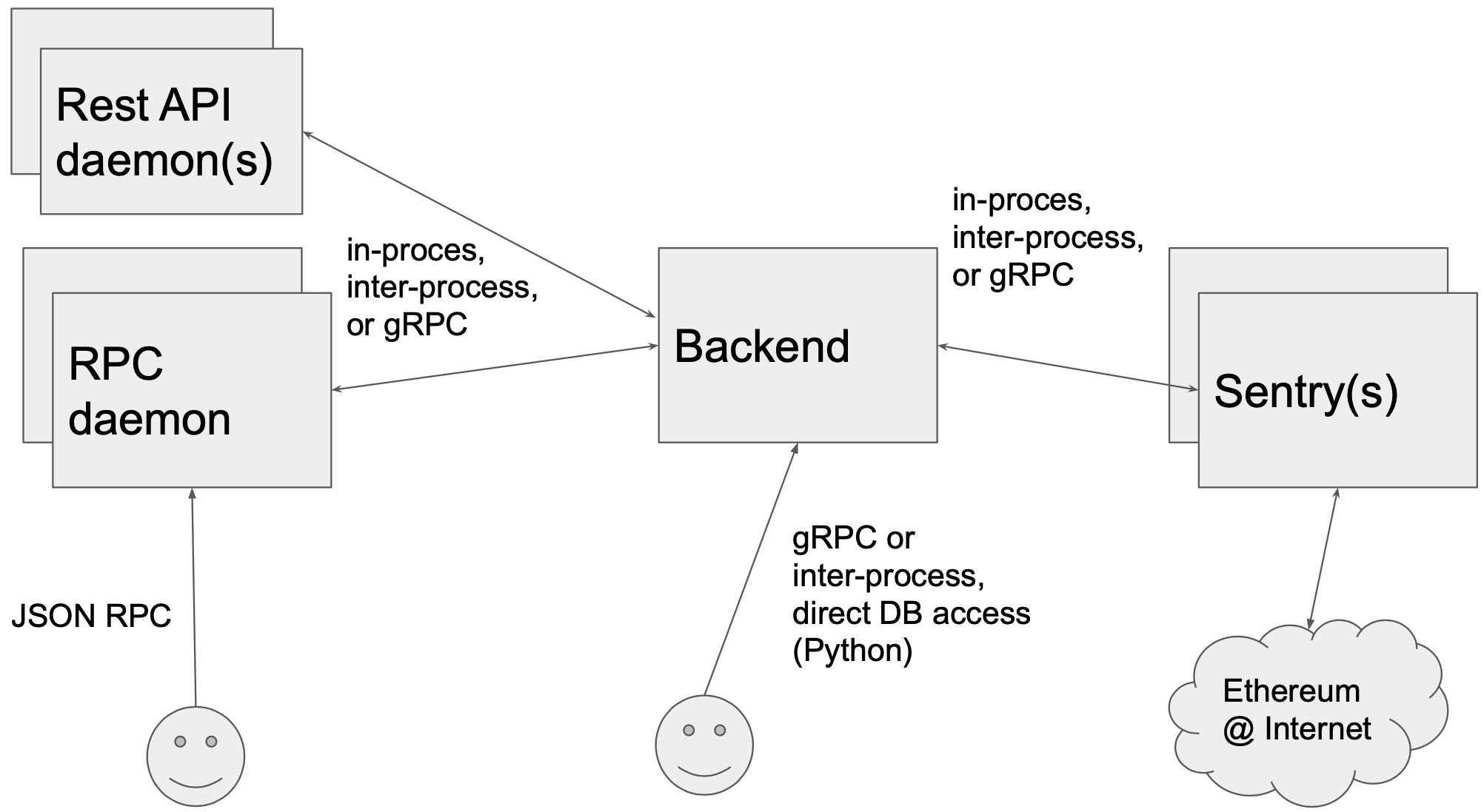
When we migrate, we will first migrate the backend, and leave RPC daemon and the Sentry using Go, and decide on their migration plans at later point.
JSON RPC API
It is mostly derived from go-ethereum, with some changes. Some methods will not be supported in the first release, for example, eth_getProof. It is possible to implement eth_getProof, and we have the implementation that works correctly, but very slowly. We do not currently consider it a big enough feature to delay the first release for. In the method debug_accountRange, turbo-geth will also be slower for the historical blocks that are very far away in the past. In methods debug_accountRange and debug_storageRangeAt, the order in which turbo-geth returns items is different from the order in which go-ethereum returns the same items.
Since these tests were done, the state and the history database format have changed again, therefore the RPC methods will need to be modified/fixed and re-tested again. The following section will be used to track the fixes and retests for these API methods.
Testnet support
We did not routinely test on Ropsten, Görli, or Rinkeby, but we did some spot checks and they appear to be working with turbo-geth
Disk space
Chart below shows approximate allocation of disk space between various buckets (you can think of them as tables in the database).
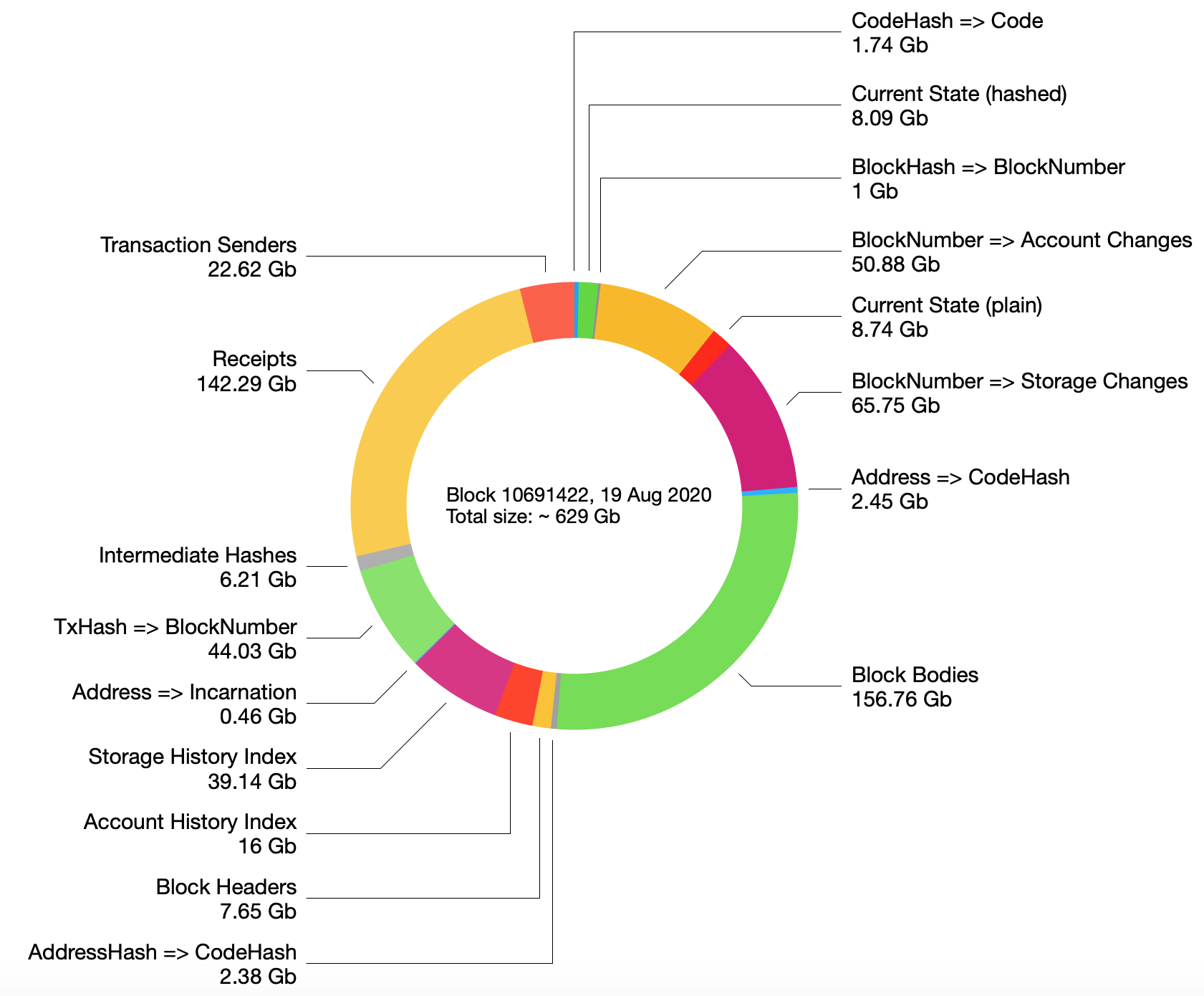
The picture above shows the total size of the database as 629 Gb, although the sum of all buckets is actually 576 Gb. We are still not sure why, most probably we forgot to include a 53 Gb bucket in the picture.
Two state buckets and no preimages
You may see that there are two buckets containing the state, one with original keys (account addresses and contract storage locations), another - with “hashed” keys. Although it might seem like a waste of space, you may also notice that there is no “Preimage” bucket that we had before. The size of preimage bucket would be roughly the same as the size of the state bucket. Why there is no preimage bucket? Because now all queries (JSON RPC, or Rest API) about accounts and contract storage can be answered from the un-hashed state bucket, without any need of preimages. Not only it is more efficient, but also allows some functionality not easily available with the “hashed” stage + preimage combination. One example is autocompletion search for addresses that you might have seen on etherscan:
You might imagine that etherscan has to maintain the list of currently active addresses to suport this, and in turbo-geth it will be built-in.
There is another way in which the un-hashed state will prove to be useful. When the snapshot sync is implemented, it is most likely be transmitting the state keys in an unhashed form, so that the receiving node can have the same advantages as the sending node, without having preimages (snapshot sync protocols do not transmit preimages).
Staged sync
So-called full-sync, or its variant archive-sync is performed by downloading all historical block bodies and replaying all transactions contained in them. Traditionally, in go-ethereum, downloading the bodies and replaying transactions happens concurrently with other activities, like verification of Proof-Of-Work in the block headers, recovery of transaction senders from their signatures etc. In turbo-geth, we have recently taken a different approach. We tried to maximally decompose the sync process into stages, and perform them sequentially. From the first sight, it might sound like a bad idea - why not use concurrency? However, we noticed that running many things concurrently obscured our ability to profile and optimise code - there is simply too much going on. Decomposition allowed us to optimise each stage in separation, which is much more tractable. We also noticed the benefit of improved code structure.
Another interesting insight became apparent when we engineered the decomposed staged sync. We could decouple the execution of transactions from computing and verifying state root hashes. Before staged sync, the computation of state root hash and its verification would happen for every single block, and this is where we saw the biggest performance drag. At the same time, we knew that nodes that fast-sync or wrap-sync, only perform such verification on the state snapshot they are downloading, and subsequent blocks after that. We took similar approach in our staged sync - in one stage, we replayed all historical transactions, advancing the current state, and only verifying receipt hashes for each block. When the state is advanced to the head of the chain, we compute state trie, verify its root hash, and take it from there. This approach allowed for the drastic reduction of the sync time.
Currently envisaged stages
At the moment we envisage about 14 stages in the “staged sync”, but more stages are likely to be added as a way of plugging more functionality. The first stage completes before the second one is started. After the last stage is complete, the control comes back to the first stage, and so on.
- Download block headers. The parent-child relationship between block headers, as well as their Proof Of Work is verified before they are written into the database. This stage is also a source of potential reorgs, when a heavier chain is detected compared to the one which is currently deemed canonical. In such situations, unwinding happens in the reverse order of the stages, from the 10th to the 1st.
- Index of block numbers by block hashes. Since block hashes look like pseudo-random numbers, inserting them into the database in the order of their appearance causes unnecessary delays on the disks with high latency of access (HDD). This stage exists to alleviate it, and it pre-sorts the index by block hashes before inserting them into the database in “one go”.
- Download block bodies. Block bodies contain list of transactions and list of ommers (uncles). The correspondence between transactions and the
TxHash in the header, as well as the correspondence between ommers and the UncleHash in the header, is verified at this stage.
- Recover transaction senders. Sender of each transaction is not explicitely contained inside the transaction’s data, but rather it is contained inside the ECDSA digital signature that comes with every transaction. The sender’s public key needs to be recovered from the signature, and then the address of the sender derived from the public key. This is what happens at this stage, and the bodies of the blocks are updated in the database to include the sender’s information, so that the recovery need not be repeated later.
- Replay transactions contained in the blocks. As the transactions are getting replayed, three types of data are getting produced. Firstly, the current state, which is the mapping of account addresses (not the hashes of addresses) to the account records, the mapping of contract storage locations (not the hashes of the locations) to the contract storage values, and the mapping of contracts to their bytecode. Secondly, the reverse diffs of the state changes - for every processed block it is a mapping of all modified state objects to the values those objects had prior to modifications. And thirdly, transaction receipts are computed, and their merkle hash is compared with the
ReceiptHash field in the corresponding header.
- Transform the “plain state” to the “hashed state”. In Ethereum, in order to maintain the state trie balanced, the keys of all entries in the state trie are pre-scrambled using
Keccak256 function. At this stage, this transformation is performed en masse, for the entire state if this is the first sync cycle, or for the state increment otherwise.
- Create or update intermediate state hashes. In order to improve performance of state root hash calculation and of generation of merkle proof, there is additional mapping of partial state key to the root hashes of the corresponding merkle sub-trees. The overhead is this structure is not very large, on the order of 15-20% of the state size. At the end of this stage, the state root hash becomes known, and it is verified against the
StateRoot field of the corresponding header.
- Generate account history index. Using the reverse diffs produced at the stage 4 (transaction replay), which are indexed by the block number, this stage creates and additional index, by the account’s address, which allows quick access to the list of block numbers in which a specific account was modified. The history index is essentially a mapping from account addresses to the sequence of block numbers.
- Generate contract storage history index. This is simular to the previous stage. The reason it is in a separate stage is that the contract storage is a bit more complex than accounts: there is one-to-many relation between contracts and their storage items, storage items can disappear in large quantities during
SELFDESTRUCT invocations.
- Generate transaction lookup index. This is the mapping from transaction Id (transaction hash currently) to the location of that transaction (currently just the block number). This can be viewed as a reindexing of the block bodies.
- Generate transaction receipts. Although transaction receipts are generated during the stage 4 (transaction replay), they are currently not persisted there, because this is an optional setting. Turbo-geth is able to serve receipts even if they are not explicitely persisted, by re-computing them on the fly from the history. This method saves space, but has a peformance penalty. The users who need quicker access to receipts in exchange for extra disk space, can enable this stage. This will effectively replay all transactions again, but, unlike in the stage 4 (transaction replay), there is no generation of current state and the reverse diffs, therefore the process is faster.
- Activate transaction pool. Before the state is synced and is accessible, there is no use of running the transaction pool logic, because for the security of the network, transactions should not be relayed unless the node can verify that there are no nonce gaps created by those transactions, and that the sender can afford to pay for gas. Activation of the transaction pool means downloading the currently active transactions from peers and initiating verification and relay.
- Activate mining. This stage will only be activated when needed.
- History pruning (likely to be split into multiple stages too)
There might be more stages added in the future.
Readiness of the stages, and an alternative plan
| Stage |
Readiness |
Further work |
Duration on Intel NUC8i7HNK up to block 10’677’851 on mainnet |
| 1. Download block headers |
WORKS |
|
1h 40m |
| 2. Index of block hashes to block numbers |
WORKS |
|
1m |
| 3. Download block bodies |
WORKS |
|
5h 30m |
| 4. Recover transaction senders |
WORKS |
|
4h 10m |
| 5. Replay transactions |
WORKS |
Optimisations on high-latency devices |
32h30m (with generating receipts), ? (without generating receipts) |
| 6. Transform plain state to hashed state |
WORKS |
More efficient support for larger increments |
1h 17m |
| 7. Create or update intermediate state hashes |
WORKS |
More efficient support for larger increments |
27m |
| 8. Generate account history index |
WORKS |
Bitmap-based indices |
55m |
| 9. Generate contract storage history index |
WORKS |
Bitmap-based indices |
1h 30m |
| 10. Generate transaction lookup index |
WORKS |
|
2h30m |
| 11. Activate transaction pool |
More tests for transaction invalidation |
|
|
| 12. Activate mining |
NOT IN SCOPE for Release 1 |
|
|
| 13. Prune history (likely multiple stages) |
NOT IN SCOPE for Release 1 |
|
|
Integration with evmone via EVMC
When experimenting with the staged sync (as described in the previous section), and decomposing the transaction execution into a separate stage, we finally saw something really “promising” in the CPU profile - EVM execution became the main bottleneck, followed by the golang garbage collector. In order to quickly reduce the allocations happening inside the built-in go-EVM, we decided to integrate evmone (https://github.com/ethereum/evmone), C++ implementation of EVM, and re-profile. This allowed us to see more clearly the allocation spots outside of EVM, and also get some experience with EVMC (C-interface to EMVs, https://github.com/ethereum/evmc) and evmone. At the moment, support for EVMC is experimental, because it still have serious performance limitation.
LMDB is default database backend
For most of the history of turbo-geth, we used a modified version of boltDb as the primary database backend.
Then we have also started experimenting with LMDB. We managed to find a configuration in which our integration with LMDB performs on par with boltDb (our version). Long iterations perform better than with BoltDB. Turbo-geth now uses LMDB by default, which bolt available as an option. We had a preference for LMDB, because it is actively maintained unlike BoltDB, and it might be a good starting point for gradually migrating functionality from Go to C++. It is likely that we abandon boltDb in the near future.
More recently, we started to think that it might be possible to achieve reasonable performance on high-latency devices even with B+tree databases.
Python bindings, remote DB access, and REST API daemon
Although JSON RPC API seems to be the prevalent way of accessing data stored in Ethereum nodes, often more flexibility is required.
Turbo-geth offers three other alternatives:
- LMDB python bindings. If you want to access the turbo-geth data from the same computer where turbo-geth process is running, you can use LDMB to open turbo-geth’s database in a read-only mode. Perhaps the easiest way to do that is via Python bindings: https://lmdb.readthedocs.io/en/release/. This, of course, requires the knowledge of turbo-geth’s data model.
- Remote interface to the database. For those who run turbo-geth on one computer, but some analytics software or other things that need turbo-geth’s data, there is remote DB access. It uses gRPC as transport, and its use requires the knowledge of the turbo-geth’s data model.
- REST API daemon. Such daemon can be run on the same or a different computer from the turbo-geth node. REST API daemon accesses the live database of turbo-geth locally or remotely, via read-only interface. There can also be multiple daemons connected to the same turbo-geth node, which can help creating more cost effective infrastructure for some users. The REST API has only couple of functions at the moment, and it is not standardised in any way, but it is a useful platforms for users who want to get their hands dirty and create bespoke interfaces for their or their clients’ needs.
Towards the first release of Turbo-geth
It has been more than two years since turbo-geth project started. Now we are almost there. This post will explain the criteria we will use for determining when the release is ready, and what to expect from turbo-geth in its first release. First, we will describe the current limitations (compared to other Ethereum implementations), and then go over things that are the reason for turbo-geth to exist - performance and architecture.
When is it going to be ready?
It is now ready for public alpha stage. We encourage people to try it out, and talk to us about results, and report issues. Though the sync (and with it, the creation of the initial database) with the Ethereum main net has been massively improved due to the new architecture, it still takes non-trivial amount of time (several days).
We call this new architecture “staged sync”, and it will be explained in more detals further down.
When are we going from “alpha” to “beta”?
Currently, the main criterion for us to go from alpha to beta is the (somewhat subjective) understanding of how “in control” of code our team is. At this moment the feeling is that we are mostly in control (meaning that we can identify and debug issues without too much digging into some unknown code), except for certain parts that pertain to devp2p, downloading of headers and blocks, and reactions on the new blocks. The code we are currently using has not been designed for staged sync architecture, and assumes that all “stages” are happening concurrently. Therefore, this code does much more than we need, and is unnecessarily complex for what we actually need. We also often experience stalling sometimes.
In order to address this, we have started a redesign of block header downloading, which should result in a more suitable, better understood code Here is current Work-In-Progress documentation (which is also accompanied by a Proof Of Concept implementation and tests): https://github.com/ledgerwatch/turbo-geth/blob/headers-poc/docs/programmers_guide/header_download.md
Distribution
We would like to keep concentrating on developing and optimising the code, therefore we will not be publishing any binaries. Our first users would need to build from source. This may change in the future, if we find it being crucial.
No fast sync, warp sync or any other snapshot sync
In the first release, the only way to synchronise with the Ethereum network will be to download block headers, download block bodies, and execute all the blocks from genesis to the current head of the chain. Although this may sound like a non-starter, we have managed to make this process very efficient. As our next steps, we would like to develop a version of snapshot sync, which is as simple as possible (as simple as downloading a file from a torrent), initial description and discussion can be found here: https://ethresear.ch/t/simpler-ethereum-sync-major-minor-state-snapshots-blockchain-files-receipt-files/7672
Work is underway on the initial code that will utilise BitTorrent for downloading headers and blocks.
GPL license
Since turbo-geth is a derivative of go-ethereum, it inherits General Public License 3.0. We will not be able to relicense the code at any point, but we may, in the future, shift some or all parts of the functionality into external libraries that would be released under more permissive licenses than GPL3.
Licence and language migration plan (out of scope for the release)
This would be an experiment which goes beyond technical, but it is rather trying to find out whether it is possible to build a financially sustainable operation around a product like Ethereum implementation. So far very few had tried and we do not see a lot of success. Lots of people believe that this lack of success has to do with the limitations of the GPL licence:
We would like to try to get to Apache 2.0 licence. But that means basically re-writing the product. And we do not see a good way of re-writing turbo-geth in Go without a lot of “rewriting for rewriting sake”, which is likely to be counterproductive. Also, going “into a cave” again and re-writing it from scratch is not something we would like to do. I would prefer gradual migration of the product that always works - in my experience this approach has much fewer risks. C++ seems to be a good first target for migration, for a few reasons:
Go => (Go;Rust) => Rustis likely to be more troublesome than the migrationGo => (Go;C++) => C++ => (C++;Rust) => Rust, though this is not currently a goal.Work is underway to convert certain stages of the sync process to C++.
Separation of JSON RPC and future of architecture during migration
Presently, turbo-geth, like go-ethereum runs most of its its functionality in a single, monolithic process. We have started some experiments on separating the JSON RPC functionality out into a separate process (RPC daemon), to support more flexible scaling of “JSON RPC farms”. We are planning to experiment with separating out another networking component, which is currently handling peer discovery and devp2p, into a separate process, called Sentry. The resulting architecture would look like this:

When we migrate, we will first migrate the backend, and leave RPC daemon and the Sentry using Go, and decide on their migration plans at later point.
JSON RPC API
It is mostly derived from go-ethereum, with some changes. Some methods will not be supported in the first release, for example,
eth_getProof. It is possible to implementeth_getProof, and we have the implementation that works correctly, but very slowly. We do not currently consider it a big enough feature to delay the first release for. In the methoddebug_accountRange, turbo-geth will also be slower for the historical blocks that are very far away in the past. In methodsdebug_accountRangeanddebug_storageRangeAt, the order in which turbo-geth returns items is different from the order in which go-ethereum returns the same items.Since these tests were done, the state and the history database format have changed again, therefore the RPC methods will need to be modified/fixed and re-tested again. The following section will be used to track the fixes and retests for these API methods.
Testnet support
We did not routinely test on Ropsten, Görli, or Rinkeby, but we did some spot checks and they appear to be working with turbo-geth
Disk space
Chart below shows approximate allocation of disk space between various buckets (you can think of them as tables in the database).
The picture above shows the total size of the database as 629 Gb, although the sum of all buckets is actually 576 Gb. We are still not sure why, most probably we forgot to include a 53 Gb bucket in the picture.
Two state buckets and no preimages
You may see that there are two buckets containing the state, one with original keys (account addresses and contract storage locations), another - with “hashed” keys. Although it might seem like a waste of space, you may also notice that there is no “Preimage” bucket that we had before. The size of preimage bucket would be roughly the same as the size of the state bucket. Why there is no preimage bucket? Because now all queries (JSON RPC, or Rest API) about accounts and contract storage can be answered from the un-hashed state bucket, without any need of preimages. Not only it is more efficient, but also allows some functionality not easily available with the “hashed” stage + preimage combination. One example is autocompletion search for addresses that you might have seen on etherscan:
You might imagine that etherscan has to maintain the list of currently active addresses to suport this, and in turbo-geth it will be built-in.
There is another way in which the un-hashed state will prove to be useful. When the snapshot sync is implemented, it is most likely be transmitting the state keys in an unhashed form, so that the receiving node can have the same advantages as the sending node, without having preimages (snapshot sync protocols do not transmit preimages).
Staged sync
So-called full-sync, or its variant archive-sync is performed by downloading all historical block bodies and replaying all transactions contained in them. Traditionally, in go-ethereum, downloading the bodies and replaying transactions happens concurrently with other activities, like verification of Proof-Of-Work in the block headers, recovery of transaction senders from their signatures etc. In turbo-geth, we have recently taken a different approach. We tried to maximally decompose the sync process into stages, and perform them sequentially. From the first sight, it might sound like a bad idea - why not use concurrency? However, we noticed that running many things concurrently obscured our ability to profile and optimise code - there is simply too much going on. Decomposition allowed us to optimise each stage in separation, which is much more tractable. We also noticed the benefit of improved code structure.
Another interesting insight became apparent when we engineered the decomposed staged sync. We could decouple the execution of transactions from computing and verifying state root hashes. Before staged sync, the computation of state root hash and its verification would happen for every single block, and this is where we saw the biggest performance drag. At the same time, we knew that nodes that fast-sync or wrap-sync, only perform such verification on the state snapshot they are downloading, and subsequent blocks after that. We took similar approach in our staged sync - in one stage, we replayed all historical transactions, advancing the current state, and only verifying receipt hashes for each block. When the state is advanced to the head of the chain, we compute state trie, verify its root hash, and take it from there. This approach allowed for the drastic reduction of the sync time.
Currently envisaged stages
At the moment we envisage about 14 stages in the “staged sync”, but more stages are likely to be added as a way of plugging more functionality. The first stage completes before the second one is started. After the last stage is complete, the control comes back to the first stage, and so on.
TxHashin the header, as well as the correspondence between ommers and theUncleHashin the header, is verified at this stage.ReceiptHashfield in the corresponding header.Keccak256function. At this stage, this transformation is performed en masse, for the entire state if this is the first sync cycle, or for the state increment otherwise.StateRootfield of the corresponding header.SELFDESTRUCTinvocations.There might be more stages added in the future.
Readiness of the stages, and an alternative plan
Integration with evmone via EVMC
When experimenting with the staged sync (as described in the previous section), and decomposing the transaction execution into a separate stage, we finally saw something really “promising” in the CPU profile - EVM execution became the main bottleneck, followed by the golang garbage collector. In order to quickly reduce the allocations happening inside the built-in go-EVM, we decided to integrate evmone (https://github.com/ethereum/evmone), C++ implementation of EVM, and re-profile. This allowed us to see more clearly the allocation spots outside of EVM, and also get some experience with EVMC (C-interface to EMVs, https://github.com/ethereum/evmc) and evmone. At the moment, support for EVMC is experimental, because it still have serious performance limitation.
LMDB is default database backend
For most of the history of turbo-geth, we used a modified version of boltDb as the primary database backend.
Then we have also started experimenting with LMDB. We managed to find a configuration in which our integration with LMDB performs on par with boltDb (our version). Long iterations perform better than with BoltDB. Turbo-geth now uses LMDB by default, which bolt available as an option. We had a preference for LMDB, because it is actively maintained unlike BoltDB, and it might be a good starting point for gradually migrating functionality from Go to C++. It is likely that we abandon boltDb in the near future.
More recently, we started to think that it might be possible to achieve reasonable performance on high-latency devices even with B+tree databases.
Python bindings, remote DB access, and REST API daemon
Although JSON RPC API seems to be the prevalent way of accessing data stored in Ethereum nodes, often more flexibility is required.
Turbo-geth offers three other alternatives: